
2026 年 6 月 17 日,成立于 2024 年的机器人训练基础设施初创公司 XDOF 解除低调状态,完成 7,000 万美元融资,投资方包括 Thrive Capital、 Spark Capital 等一众知名投资机构。
几乎在完成融资的同时, XDOF 发布迄今最大的开源遥操作数据集之一—— ABC-130K :13 万条轨迹、195 个任务、3,500 小时真实世界数据。
然而,更大规模的遥操作数据,并不意味着 VLA 模型能够自然获得稳定的长周期操作能力。
目前,长周期任务面临的关键瓶颈是记忆与决策的时间跨度——模型需要在成百上千个时间步中记住关键状态、忽略冗余帧、在正确的时机做出决策。
为此,2026 年 6 月 22 日,由 Yihan Zeng 为第一作者发布了一篇论文《KEMO: Event-Driven Keyframe Memory for Long-Horizon Robot Manipulation with VLA Policies》,作者名单中包含 XDOF 联合创始人之一 Philipp Wu。
论文聚焦一个当前 VLA 领域最棘手的问题之一——长程操作任务中的记忆缺失,并推出 KEMO 作为 VLA 解决该问题的「外挂模块」。

KEMO 帮 VLA 做了什么
机器人在完成长程任务时,常常面临「在执行任务的不同阶段观测到相似的视觉信息」的问题。
过去,为解决该问题,无论是通过「token 合并」、「循环状态」、「固定大小的隐式表征」等方式来压缩存储过去的所有历史帧,或者是使用视觉语言模型(VLM)来分解长任务,都会不可避免地增加额外的推理成本,甚至带来任务分解过程所造成子目标描述的错误。
对此,文章推出了一种用于长程操作的插件式记忆框架—— KEMO 。KEMO 的原则是找出任务阶段状态转换的「事件关键帧」,并且提供紧凑且明确的历史证据,用于消除不同阶段的视觉相似引起的歧义,以支持对应阶段的动作预测。
KEMO 框架主要包括两个部分:「检测关键帧」和 「集成关键帧」。
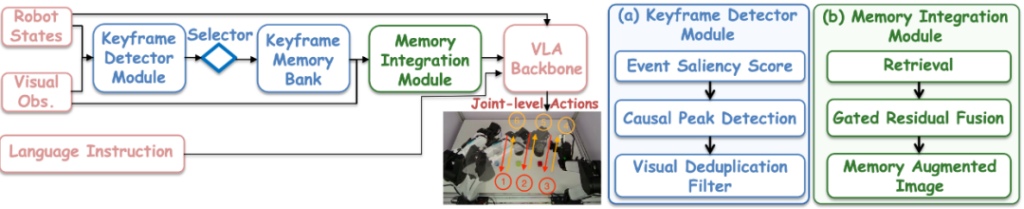
- 检测关键帧
首先,设计事件显著性函数,将机器人关节位置信息作为输入,当出现抓取、放置等关键操作事件时,关节移动速度减慢(通常任务进行到下一阶段,关节会刻意减速),函数输出值将增大。
接着,通过检测上述函数输出序列是否在一段时间内产生局部峰值,并将产生了局部峰值对应的机器人关节减慢时刻,称为候选事件关键帧。
最后,为避免机器人可能因为调整姿态或短暂停顿而产生运动减速信号的干扰, KEMO 使用冻结的 DINOv2 编码器计算候选事件关键帧与最近已接受的事件关键帧之间的视觉差异度,当视觉差异大于某个阈值,该候选帧才会被接受。
通过以上三步,KEMO 可以在没有任务特定标注的情况下可靠地识别事件转换阶段。
- 集成关键帧
首先,使用与基础策略相同的 SigLIP 视觉编码器对关键帧图像进行编码,并应用 4×4 的空间平均池化将每个关键帧编码的 256 个 token 降低到 16 个,以降低计算成本。
接着,把每个关键帧的 16 个压缩 token 存入一个时序记忆库,库中的每个关键帧槽位接收一个「可学习的时间位置嵌入」,该「嵌入」会把时间信息广播到其余 16 个 token 中,解决了「第一个盖杯子的画面」和「第二个盖杯子的画面」视觉相似但时序含义不同的问题。
最后,通过交叉注意力引入记忆,即让当前观测的「视觉 token」去检索时序记忆库中的「事件关键帧 token」,并且通过一个门控残差结构,当随着训练推进、记忆 token 变得有信息量,门控逐渐开放,记忆信息被选择性融合进 VLA 的语言模型骨干。
本质上,KEMO 没有重新设计 VLA ,也没有让语言模型直接「读」记忆。它只是在视觉特征进入语言模型之前,用交叉注意力做了一次「历史检索」,用门控残差做了一次「信息筛选」,然后把丰富后的视觉表征原样交给后续训练。

KEMO 具体效果如何
所有实验在真实世界的 YAM 双臂机器人上完成。 YAM 是一种双臂协作机器人平台,每臂具有多自由度。实验使用多相机 RGB 观测和关节位置作为机器人状态输入。
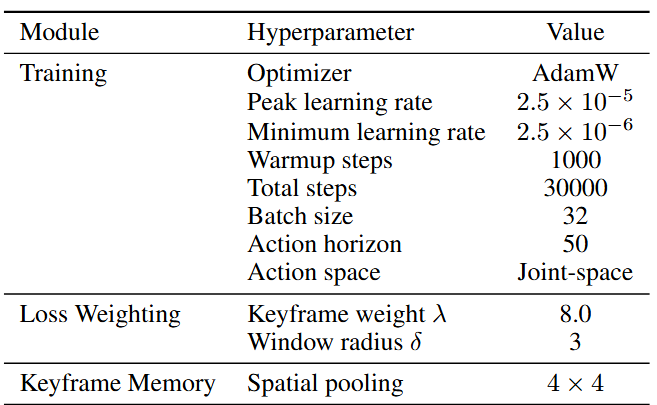
KEMO 框架策略是以预训练的 VLA 骨干网络 π0.5 为初始化,并在采集的演示数据上通过有监督微调(SFT)进行精调。补充说明一下这个损失加权(loss weighting),图中表示的是将每个事件关键帧的 3 个时间窗口的权重提高 8 倍。
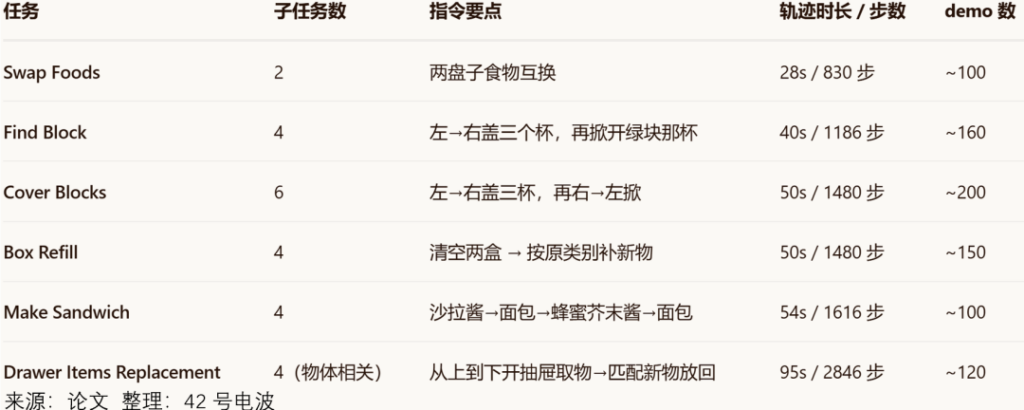
该策略与在相同的演示数据上进行微调却未采用记忆增强的 π0.5 ,以及另一个记忆增强策略 MemoryVLA 在以下 6 个任务中作对比试验。
此处对 MemoryVLA 作必要补充,MemoryVLA 是受认知科学启发的双记忆框架,利用传统 VLM 编码构建感知-认知记忆库,并通过检索融合机制生成动作。与 KEMO 相比,MemoryVLA 依赖通用 VLM 标记构建密集记忆,而 KEMO 是轻量插件级框架,仅存储稀疏记忆。
实验结果对比也相当明显,在所有任务中, π0.5 平均实现了 27.8% 的总体 TSR(任务成功率),而 MemoryVLA 实现了 1.4%。相比之下,我们的方法实现了 51.4% 的平均任务成功率,相对于 π0.5 提升了 23.6 个百分点。
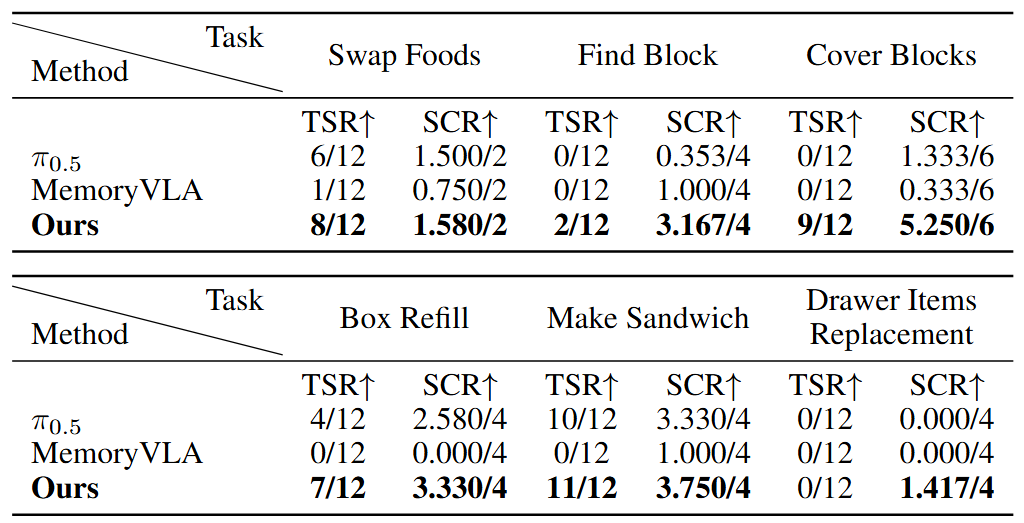
我们的方法还将 SCR (阶段完成率)从 42.3% 提高到 76.4%,提升了 34.1 个百分点。这些结果表明,所提出的 KEMO 框架策略改善了跨任务的成功率和完成进度。
最后消融实验(移除某个模块,看对整体的任务的影响实验)证明,「门控残差融合」、「损失加权」都对整体任务完成度有着不少的影响。
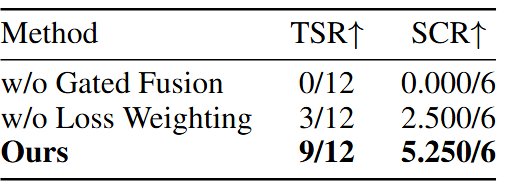
特别是移除损失门控后,任务成功率从 9 次直接调到 0 次,此时记忆特征将主导视觉表征,说明记忆只能作为当前的补充,而非替代,也与 KEMO 即插即用的设计哲学吻合。

为何说它值得关注
首先,训练一个更大的 VLA 基础模型(如将 π0.5 的参数规模翻倍)需要的不仅是计算资源,还需要更大模型需要更多、更多样的训练数据,甚至需要更复杂的训练基础设施,而且推理延迟会线性或超线性增长。
对于一个已经在生产环境中运行的机器人系统,更换更大的 VLA 模型可能意味着需要重新评估整个硬件-软件栈。
而论文中 KEMO 是在 π0.5 的基座上构建的,但架构设计上 KEMO 的四个组件(关键帧检测器、记忆编码器、门控融合层、损失加权)不依赖 π0.5 的任何特定属性。
事件关键帧检测只依赖关节位置和 RGB 图像,记忆编码共享 VLA 的视觉编码器(SigLIP),门控融合不改变 VLA 的语言模型骨干。
这意味着:理论上,KEMO 可以接入任何使用 SigLIP(或类似视觉编码器)的 VLA 策略。但需要注意一个工程细节:KEMO 目前使用的是 SigLIP 作为视觉编码器。如果目标 VLA 使用不同的视觉骨干(如 CLIP、InternViT),则需要调整记忆编码器以匹配。这不是架构限制,但需要工程适配。
从工业上看,论文中验证 KEMO 能力的 Cover Blocks、Box Refill 和 Drawer Items Replacement 本质上都是装配任务的变体——「覆盖-揭开」对应装配-拆卸,「重新填充」对应按类别补料,「抽屉物品替换」对应零件更换。
从家庭场景中看,KEMO 的当前设计验证:基于事件检测的短期(单任务内)记忆,离家庭的长期记忆需求还有很长的距离。
特别是,当前 KEMO 的关键帧仅包含 RGB 图像。触觉、力觉、声音——这些模态在精细操作中携带丰富的任务进展信号,但目前的记忆系统尚未利用。
但它的核心架构原则(存储关键事件,而非密集记录所有历史帧)可能是构建更大规模、更长跨度记忆系统的基础。
总之,KEMO 以其即插即用的轻量插件设计和事件驱动的增强记忆机制,高效满足了 VLA 在长程操作中对执行历史的记忆需求,或许侧面表明无需依赖复杂世界模型,仅靠精炼的关键帧记忆即可显著提升时序推理能力。