
最近,美国具身智能公司 Physical Intelligence 的联合创始人 Quan Vuong 参加了 YC 团队的播客节目,在近 1 小时的访谈中,Quan Vuong 就机器人的 ChatGPT 时刻、数据瓶颈、云端推理等问题进行了详细探讨。
在具身智能这条赛道上,PI 其实算是一个异类,不造机器人本体,主要做软件。
这家公司想做的是机器人世界里的智能基础设施,给本体厂商提供模型,就像云计算之于互联网创业,把技术变成一种随取随用的服务。
在训练模型最大的数据难点层面,Quan Vuong 认为数据的规模化极其重要,在规模的支撑下,模型就可以学到机器人的通用控制逻辑,从而适配各种硬件本体,并非只能在某一台机器人上运行。
另外,基于一个模型控制不同机器人的前提,PI 选择了将模型部署在云端的思路,让真正的感知、推理和决策,都在云端完成。
而这些细节的背后,其实就藏着 PI 想做机器人操作系统平台的野心。

何为机器人的 ChatGPT 时刻?
过去一年来,随着机器人能力的快速提升,大家开始越来越多的谈起机器人的 ChatGPT 时刻什么时候到来。在这个问题上,每个人都有自己的理解,但本质上都是在期待一个通用能力的奇点时刻。
而 PI 联创 Quan Vuong 认为的机器人 ChatGPT 时刻是这样的:「打造出真正智能的模型,再搭建平台,把它开放出来,让大家基于此开发各类垂直机器人应用。」

其实这也跟 PI 这家公司的定位有很大关系,在具身智能这条赛道中,PI 的主要业务是在软件层面,目标是给机器人厂商提供模型,类似于智能驾驶赛道中给汽车厂商提供智驾软件的公司。
只不过目前具身领域很多厂商都会选择自研模型,不同厂商的机器人本体对于模型的要求也会有很大的差别,所以 PI 一直以来想做的就是一个模型,适用于各种机器人本体,这就是他们对于模型的跨本体性能如此重视的原因,毕竟这关乎着公司的商业化能力。
在这里,Quan Vuong 提到了此前 Google Robotics 等团队在 2022 年提出的 SayCan 模型,核心是让大语言模型(LLM)给机器人「说」合理动作、再由机器人确认能否执行。

SayCan 带来的框架其实是现在很多主流 VLA 模型的雏形,它证明了大语言模型的常识知识可以为机器人所用,这让机器人的研发对于数据采集的需求逐渐降低。
不过即便是如此,机器人所需要的数据相比较 LLM 来说,数据规模仍然是偏小的。
LLM 有大量的互联网数据使用,可具身领域不能只靠这些,真机数据、人类第一视角数据等都是重要的数据来源,这些都需要花费大量精力来采集,甚至成为了当下行业的一大卡点。

从数据规模中学习控制逻辑
在早期 SayCan 将 LLM 的知识带给机器人后,PaLM-E 与 RT-2 这两项研究则让规划转化为了机器人可执行的底层动作,只不过它们只对特定的机器人有效果,跨本体能力不行。
机器人应用要想规模化,这种跨本体能力就显得非常重要,在这个基础上,数据采集的规模化就是急需处理的事情。

Quan Vuong 认为模型在数据中学到的东西是什么,是更重要的问题。
所以他强调了数据要有足够规模,只有规模上去了,模型从数据中就能学到抽象的通用控制逻辑,从而控制各种机器人本体。
只不过 LLM 的崛起,很大程度上靠的是「互联网」这座天然数据矿山。而机器人面对的,则是一片还没有什么人开采的荒地。
Quan Vuong 就直接点出了这个问题:
- 第一层是数据生成。现实世界里每天都在产生大量机器人操作数据,工厂里的机械臂、仓库里的分拣机器人、实验室里的遥操作记录。但这些数据绝大多数没有被系统地采集、整理,更没有被用于训练。
- 第二层是数据适配。即便数据采集上来了,不同硬件平台的数据也难以直接通用。单平台积累的数据,换一台机器人可能就失效了。
这两层叠在一起,就是机器人「数据飞轮」没有真正跑起来的关键原因。
但这道坎并非无解,Quan Vuong 给出的答案是跨硬件训练。
具体逻辑是,当模型被迫学习来自不同机器人本体的数据时,它没有办法依赖某一台机器人的具体特性,只能去学习更抽象的控制逻辑,什么是「抓住」,什么是「放下」,什么是「施加适当的力」。这种抽象化,反而让模型更能适配硬件之间的差异,而不是被这些差异所困住。
对他们来说,这是公司商业模式能否成立的前提,如果模型只能在一种机器人上工作,PI 就没有办法成为机器人界的智能层。
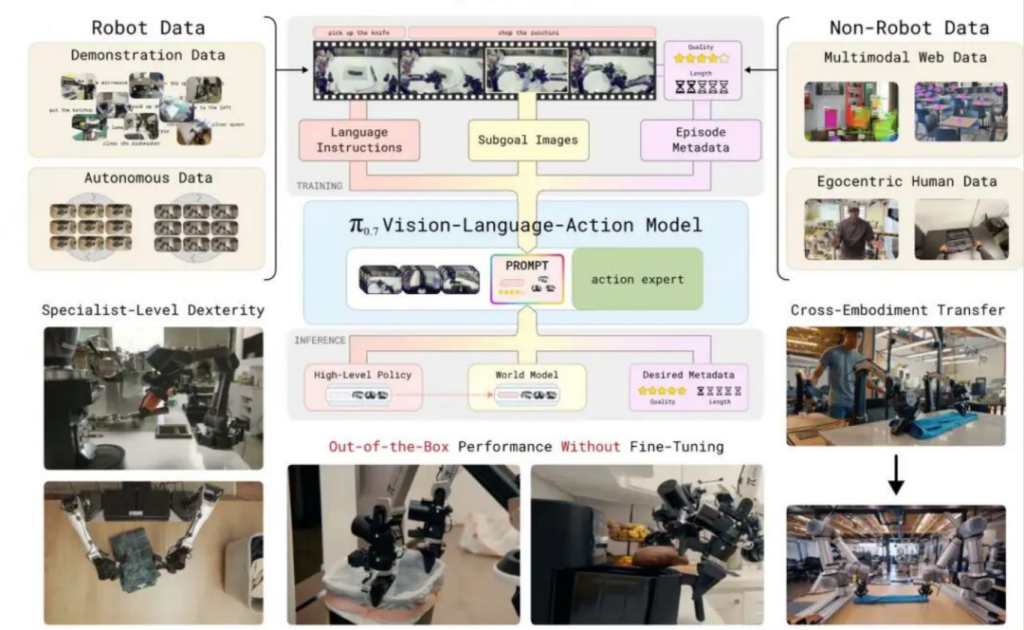
这条路走通了多少,从PI 最新发布的 π0.7 模型表现来看,已经有了切实的依据。
在最新演示中,π0.7 在叠衣服时,训练数据里并没有 UR5e 叠衣服的样本,但它的完成度达到了 85.6%。成功率接近有丰富遥操作经验的人类第一次上手时的水平。
一年前,这些任务可能还需要在对应硬件上收集数百小时数据才能实现。
这背后,是模型开始出现 Quan Vuong 所说的涌现能力,不是靠记住训练数据里的每一个动作,而是真的「理解」了任务结构,能够在新场景下举一反三。

模型选择部署在云端
在规模部署机器人的问题上,很多企业的第一反应是配置算力硬件等方面。
这个问题本身可能一个陷阱,Quan Vuong 在访谈中直接点破了这一点,今天买的芯片,两年后可能已经落后一代。把重金押在硬件上,是一种偏高风险的行为。
PI 的选择是反其道而行之,把大脑放在云端,让机器人本体尽可能「轻」。
PI 对外的能力演示,背后的模型全部运行在云端,机器人的工作流程被简化,核心的感知、推理、决策,都通过 API 调用完成。
这意味着机器人本体不再需要堆叠重型计算单元、高功耗芯片等,只需保留基础的执行能力。硬件变轻了,成本降了,迭代的压力也从机器人厂商身上转移到了云端模型这一侧。

有一个故事,Quan Vuong 在访谈中特别提到,颇能说明问题。
PI 与 Weave、Ultra 的合作过程中,合作方机器人本体的硬件细节他本人故意不去了解,但模型可以丝滑接入,不需要定制适配,就能直接跑起来。
这种「硬件无关性」,正是 PI 商业模式规模化的关键前提。如果每接入一家新客户都要重新适配一次硬件,PI 的模式就永远只能是定制服务,而不是平台。

写在最后
作为一家主要业务在软件上的具身公司,PI 的发展逻辑和那些全栈自研的厂商天然不同。
在很多厂商更加强调硬件为 AI 设计、硬件也属于模型设计一部分的思路下,PI 其实也面临着非常大的市场压力。
这条路能不能走通,本质上是一个关于「行业分工」的理解。
全栈自研走的是硬件和软件深度耦合,协同优化才能把性能做到极致。像特斯拉、Figure 等厂商都在走这条路,自己造身体,自己训大脑。
PI 押注的是另一个方向,分工比垂直整合更有规模效应。就像没有人会怀疑操作系统的价值,智能层和执行层的解耦,可能才是机器人行业真正规模化的前提。
但这个判断能否成立,有一个绕不过去的前提,模型的跨本体能力必须足够强,强到硬件厂商觉得「用 PI 的模型比自研更划算」。π0.7 展现了一定的组合泛化和跨本体能力,但在大规模落地应用层面,可能还有很长的路要走。
对 PI 来说,留给他们证明「软件路线能赢」的窗口,可能比想象中更窄。