
近年来,VLA 模型越来越强,但始终存在一个关键现实,几乎所有亮眼成绩,都依赖后训练。预训练模型本身,很少能直接部署到机器人本体上。
似乎任务微调才是那个让模型真正「干活」的东西,预训练到底有没有让机器人学会操作,离了后训练,模型还能不能直接部署到机器人上?这个问题此前并没有答案。
而在最近,自变量机器人开源了其具身基础模型 WALL-OSS-0.5,预训练模型可以直接部署到自变量自研的机器人本体上,完成搬运、分拣、整理绳子等多种操作任务,甚至一些效果能够达到不少模型需要微调才能触及的水平。
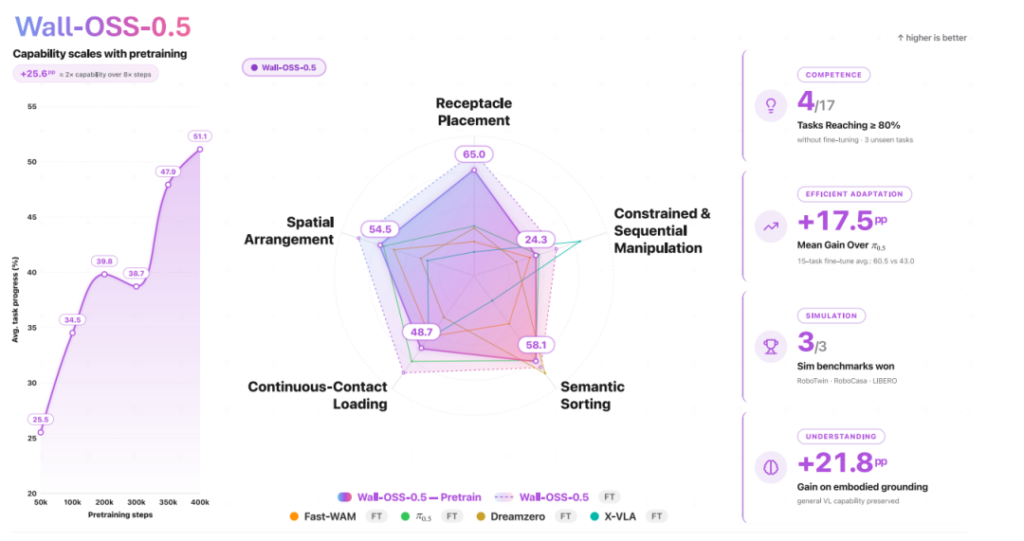
并且把这些结果放在一起看,会发现 WALL-OSS-0.5 正改变着「离开后训练,模型就不能直接用」的思维惯性。
在行业内普遍看重后训练的背景下,为什么 WALL-OSS-0.5 预训练的效果可以比肩后训练, 而 WALL-OSS-0.5 与传统的 VLA 模型相比,在设计上又有哪些不同?

为什么过去的 VLA 都需要后训练?
近一两年中,整个行业中出现了非常多的 VLA 模型,但其中绝大多数的训练范式,本质上还是视觉语言模型 + 一个外挂动作专家,它们的设计流程通常是这样的:
- 先用互联网海量图文数据训练一个 VLM(视觉语言模型);
- 然后在顶部再接一个 Action head(动作专家),专门负责动作预测;
- 最后用机器人数据单独训练动作模块。
这三个步骤看起来逻辑非常流畅,但这里其实埋着一个问题,主干模型自己并不会动作。它学的是世界知识、视觉理解和语言能力,动作能力则被放在外挂模块里。
所以在经过行业的不断实践下,大家逐渐发现,机器人主干模型规模越来越大,但真正负责执行动作的,其实还是后面那个相对小的 Action expert。
这就像一个博士负责理解世界,一个实习生负责动手,博士懂很多,但不会干活,真正干活的,是后面的小模块。
所以不一定模型越大,动作就会越强,因为「看」和「动」本身并没有真正长在一起。
这也是为什么,绝大多数 VLA 模型,都需要针对具体任务重新后训练。
因为预训练阶段,主干模型其实并没有真正掌握如何操作,它只是一个较强的视觉语言理解器。
而 WALL-OSS-0.5 的核心之一,其实就是让主干模型本身学会动作。

WALL-OSS-0.5 让不同信号各归其位
WALL-OSS-0.5 模型瞄准的核心命题是让 VLM 主干真正习得可泛化的动作能力,为此,它必须依次解决三个递进的建模问题。
如何让动作真正进入主干模型
要让预训练模型具备零样本能力,一个前提是动作不能只存在于外挂模块,它必须进入基础模型本身。
为此,WALL-OSS-0.5 做了一步非常关键的设计,把动作 Token 化,然后塞进语言模型训练。
团队提出了一个叫 Gradient-Bridge 的设计,因为过去的 VLA 是图像到主干,再到动作头,动作监督停留在 Action head。
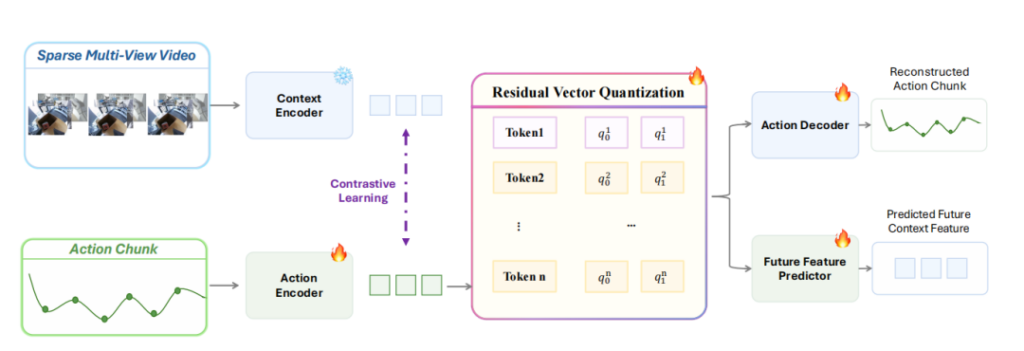
在 Gradient-Bridge 后,现在变成了图像 + 文本 + 动作 Token 到同一条自回归序列,动作也像语言一样,被预测。模型用交叉熵损失去学习动作 token,并让梯度直接反向更新主干模型。
这里的变化也让主干自己开始学习怎么动,让主⼲在预训练阶段就把看、说、动统⼀在同⼀套表征⾥。机器人动作不再是外挂能力,而是基模的内生能力。
当主干真正学到动作,预训练模型才可能拥有零样本迁移能力,否则各种新任务,都只能靠后训练补。
论文中的消融实验也很直接,一旦拿掉 Gradient-Bridge,真机成功率会出现明显下降,而且模型越大,退化越严重。也就是说模型越大,动作监督进入主干就越重要。
动作 Token 不能只是数字压缩
在整个设计中,仅仅把动作 Token 化,其实还不够。这里还有一个隐藏问题,主干到底学到的是「动作语义」,还是「动作编号」?
如果 Token 只是机械压缩后的数值编号,那模型预测动作 Token,本质上只是在猜下一个数字,并不是理解这个动作会让画面发生什么变化,这样一来,Gradient-Bridge 传进去的只是一堆无意义编码。主干学到的仍然只是统计规律,不是物理世界的可操作结构。
对此,WALL-OSS-0.5 选择重新训练一个视觉对齐的动作 tokenizer,核心逻辑是一个动作 Token 不只是动作本身,它还要知道这个动作会让世界如何变化。
于是团队强制 Token 表征与视觉特征对齐,并要求它预测下一帧视觉变化。这能让每个动作 Token 同时承载两层含义,分别是动作压缩信息和世界变化信息。
在这样的设计下,机器人就会预测接下来世界怎么变化,而不是简单的数字。
怎么让连续动作真正学会「关键轨迹」
让主干理解动作语义的过程中,还有一个比较现实的问题,机器人最终执行的,依然是连续动作,并不是 Token。
在这方面,WALL-OSS-0.5 用的是 Flow Matching(流匹配),不过这里的设计跟传统 Flow Matching 不太一样,因为传统方式往往会有些「平均用力」。

机器人的轨迹里有些部分非常关键,有些则无关紧要,比如机械臂抓杯子的任务,真正重要的是对准杯口、靠近路径和抓取姿态,一些高频细节抖动,往往不影响结果。
但传统 Flow Matching,会花很多预算去拟合这些高频噪声,于是模型大量算力就浪费在了不重要的东西上。
所以 WALL-OSS-0.5 在这方面做了一些变化:不预测速度,改成直接预测动作。
对应的结果是训练会天然更关注关键轨迹结构,而非无意义抖动。
也就是说它让模型把学习预算花在了怎样完成任务上,并不是复刻每一个细枝末节。
最后一道关卡:把训练真正跑起来
经过以上这些设计后,让训练真正运行起来就成为了更重要的事情,但三项改进聚合,也带来了一个伴生的工程问题,模型内部参数尺度与梯度强度都高度异构,因为:
- VLM 主干来自预训练
- Action head 从头训练
- 多路损失一起优化
梯度尺度会严重失衡,于是团队又做了一个系统层优化,DMuon。
本质是把高效优化器 Muon 的巨大开销,压缩到几乎可忽略。从原本接近 2x 训练成本,降到 0.02x,能够凭借即插即用的方式嵌入现有流水线。
与传统的 VLA 模型相比,WALL-OSS-0.5 所做出的改动相当之多,而这些改动所带来的能力,也在具体的任务执行中,得到了体现。

具体效果到底如何?
在团队进行的实验中,WALL-OSS-0.5 展现出了最核心的零样本泛化能力。
在覆盖语义操作、柔性操作、长程任务的多项真实机器人测试中,未经任何微调,模型预训练完成后直接部署到真实机器人上。
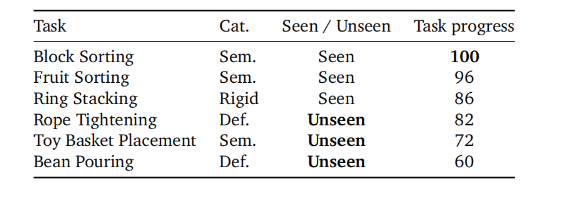
最后取得的结果是,像积木分类、水果分拣、圆环套柱任务的任务进度均超过 85%,就连训练数据中未曾出现过的绳索拉紧这类可变形物体任务,也达到了 82% 的任务进度,这在目前开源的 VLA 模型中并不多见。
而在十余个真实机器人任务公平对比实验中,所有模型使用相同的数据和微调预算。

结果显示,Wall-OSS-0.5 在操作类任务上大幅领先 π₀.₅ 等同类开源模型,领先幅度超过 25 个百分点;在需要推理判断的任务上也保持了稳定的优势。
并且值得注意的是,模型的多模态理解能力并未因侧重动作训练而崩溃。尤其在与机器人执行高度相关的具身定位(即在机器人视角下准确指出操作目标位置)任务上,Wall-OSS-0.5 相比原版 VLM 骨干提升了超过 20 个百分点。
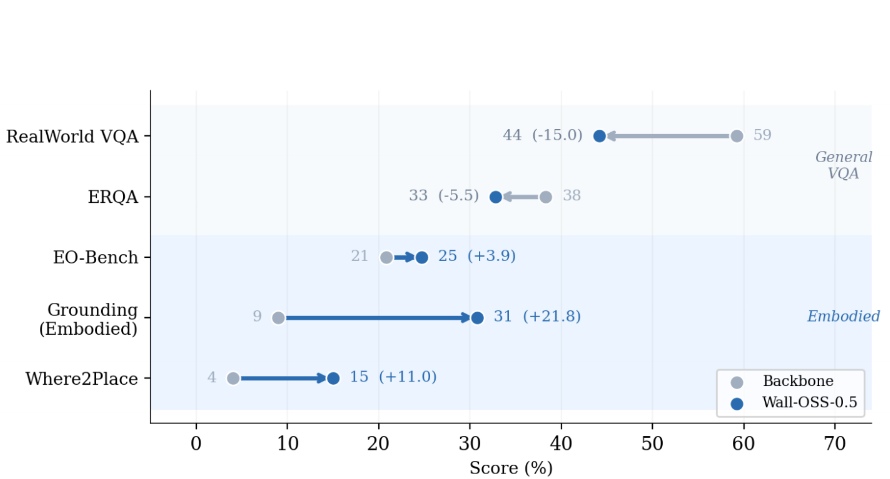
团队认为,这恰恰印证了其「梯度桥接」协同训练方案的有效性,动作学习与视觉语言理解并非零和博弈,而是可以相互促进的。

预训练即策略,为行业打开新思路
在过去很长一段时间里,受到 LLM(大语言模型)的影响,具身领域的 VLA 模型也沿袭了一条相似的路径,预训练只是给模型一个「好底子」,真正的干活能力要靠下游任务微调才能激发出来。
于是,行业内默认了一个假设,预训练权重再好,不上真机微调就不算可用的策略。
但 Wall‑OSS‑0.5 的发布,正在试图打破这个惯性思维。
从这些任务表现中可以看到,基于自变量自研的机器人本体,预训练模型开始展现出了「直接部署」的可能性,对于具身行业来说,这算是一个重要变化。
过去行业默认的路径是先预训练,再针对具体任务适配,最后才进入真实场景。
而 WALL-OSS-0.5 所尝试的,则是另一种方向,让模型具备预训练即部署的能力。当然,这种能力的出现,并不是简单依赖「更大模型」实现的。

为此,自变量团队对模型进行的设计改变,也相对彻底,不管是 Gradient-Bridge 协同训练、视觉对⻬的动作分词器、动作空间 Flow Matching,还是推进训练真正跑起来的 DMuon 优化器,这些都给了行业一个新的方向来审视 VLA 模型,该如何更好地走入真实世界中去。
不过需要注意的是,在机器人零样本任务中,Wall-OSS-0.5 所展现出来的能力,是在自变量机器人本体上完成的,如果要跨本体使用,并保持其性能,仍然需要一定程度的微调。实验也发现,对于差异较大的本体,效果差异也可能会较大。因此,跨本体的通用操作能力是未来值得重点关注的方向。
另外,团队对于每一个设计,都配套了消融实验和工程验证,说明每个模块究竟解决了什么问题,以及删掉后会带来怎样的性能变化。
而且在工程侧,团队也同步开放了 DMuon 优化器等系统级基础设施。所以这次 WALL-OSS-0.5 的开源,更像是一套具备可复现性的训练方法论公开。
对于希望训练大规模 VLA 模型的研究者来说,这种能够直接复用到训练流水线中的基础能力,进一步降低了社区复现和扩展的门槛。
这也意味着大家不再只是重复造轮子,而是有机会站在同一个起点上加速迭代。
对于整个具身智能行业来说,大家所面临的问题往往是一致的,而将机器人带进人们的生活中,又是行业的共同目标,所以开源生态、协同共进,也是行业近来发展的主线。
项目链接:https://x2robot.com/oss#resources
论文地址:https://x2robot.com/api/files/file/wall_oss_05.pdf
代码仓库:https://github.com/X-Square-Robot/wall-x
模型权重:WALL-OSS-FLOW / WALL-OSS-FAST(Hugging Face)