
小脑之于人体,如同 AstraBrain-WBC 0.5 之于机器人 —— 负责全身运动控制。
6 月 19 日,银河通用正式推出全球首个面向人形机器人的通用小脑基础模型—— AstraBrain-WBC 0.5。该模型被定义为人形机器人全身实时运动控制领域的开创性大模型,凭借扩展至 8,040 万参数级别的模型规模,成为该领域当前首个达到 GPT-1 量级的模型。
在先前工作中,人形运动追踪面临一个长期矛盾:敏捷性与泛化性相互制约。即擅长做高动态运动任务的追踪器往往在未见过的风格或场景中失效,而泛化性较好的追踪器又往往无法拟合那些对敏捷度要求高的任务,特别是当这些任务包含复杂动力学规律。
研究团队判断该矛盾的根本问题在于:「数据规模不足」和「训练流程的设计不匹配」,并推出 AstraBrain-WBC 0.5 ——一个围绕「扩展定律」(Scaling Law)构建的通用在线人形运动追踪器。接下来,将逐步拆解该模型,并展示其在真机上的真实部署效果。

模型用架构创新「吃下 20 亿帧数据」
首先,银河通用研究者构建了首个新量级的运动语料库:包含 Lafan1、AMASS、Motion-X++、PHUMA、MotionMillion 等所有主流动捕源,再加入大规模的团队采集到的真实世界数据,经严格过滤、分割、增强后,得到 20 亿帧 Unitree G1 重定向运动帧。
接着我们考虑如果将 20 亿帧直接塞进一个 PPO 策略会发生什么?报告指出单一 MLP 在 1 亿帧附近就出现性能饱和,且数据边际收益急剧递减。其中根本原因是 20 亿帧里混杂着走路、跑步、翻滚、跳舞、武术等异构动作,一个策略同时学所有这些模式会出现「常见运动风格主导」和「罕见能力缺失」。而 Humanoid-GPT 之所以能撑住这个量级,靠的是三层架构创新接力:数据层分流、多专家时序层承接、训练层高效消化。
- 数据层分流
研究人员将每个人体运动序列映射到 Unitree-G1 人形机器人的 29 自由度关节空间,并过滤显式物体交互的序列(如爬楼梯、游泳等),先确保人形在平坦场景的驱动能力,进一步对序列作时间扭曲(均匀加速或减速)增强,大幅扩展了训练集的规模,最终用于后续强化学习的专家训练。
- 多专家时序层承接
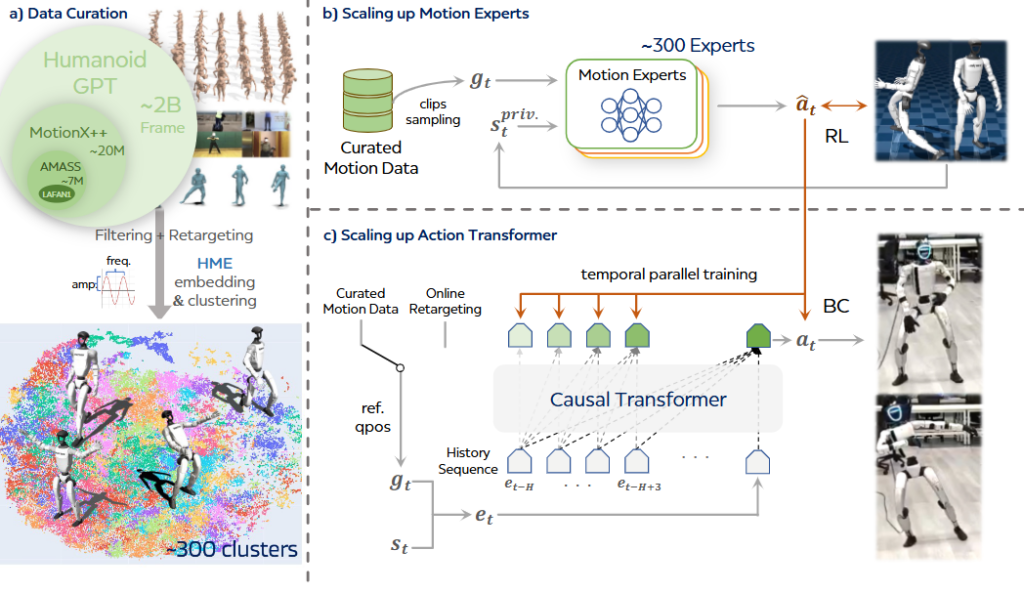
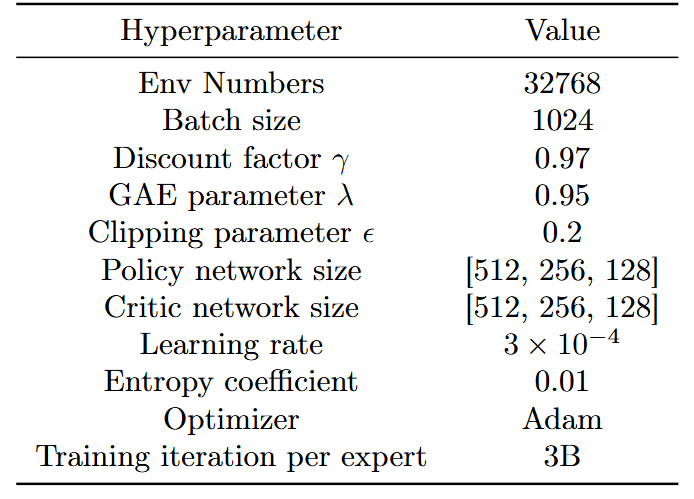
研究者通过在不同数据分区中作谐波运动嵌入(HME):先从每条运动序列中提取逐关节周期振幅与频率;再整理得到这些关节级谐波特征的均值与标准差,作为其 HME 向量;最后做 K-Means 聚类,得到约 300 个运动簇,每个簇包含约 1,000 – 2,000 条序列,并在每个簇上训练基于强化学习的运动专家。以下为运动专家超参配置。
- 训练层高效消化
不难想到,每个运动专家可在自身簇内精准复现机器人物理运动,但在遇到分布外运动目标时的性能将急剧下降。
为此,银河通用研究者的解法是先把蒸馏重构成时序建模问题,把带有「本体感知信息」、「目标参考姿态的信息」输入带时间因果掩码的 Transformer,使其有类似 Transformer 关注不同长度历史上下文的能力,从而避免 MLP 的「每次只能关注一个时刻的状态切片,对更长的历史序列只能靠拼接来临时凑数」的局限,最后采用 DAgger 框架将所有运动专家的知识蒸馏到一个通用策略中,显著提升训练效率。
研究者很好的利用了 Transformer「关注历史上下文」的能力和「适配多步并行监督」的结构,为「数据规模不足」提供了解决方案。

机器人运控领域是否存在「扩展定律」
先前在语言与视觉领域的通用路径已证明「扩展定律」(更大的数据、更大的模型、精心设计的训练目标)是模型泛化的可靠保障。同时,「扩展定律」不仅能提升平均性能,还会解锁出新的能力(比如 GPT-3 突然会做三位数加法等)。
而具身智能体的人工通用智能本质上是一个泛化问题,因此我们必须验证机器人领域是否存在同样的「扩展定律」来解决具身智能的泛化问题。
- 用数据规模来验证
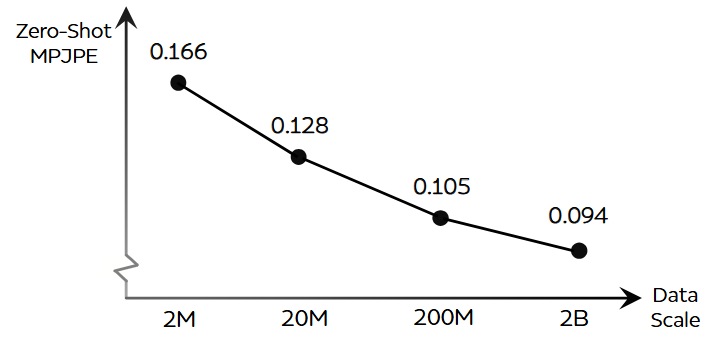
研究者用四个量级的数据(横坐标)训练 Humanoid-GPT-B 架构模型,纵坐标是 Zero-Shot MPJPE(零样本平均关节位置误差),数值越小代表机器人动作越精准。结果是一条单调下降的曲线,且没有出现「收益递减」拐点,证明了数据规模的暴力扩容能够转化为物理控制精度的提升,或许不存在所谓的「物理数据墙」。
- 「Scaling Law」与架构相关
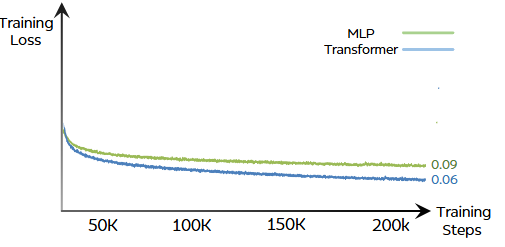
在证明了数据规模的扩容能直接提升模型的控制精度后,我们一定会思考 MLP 为什么不遵循「扩展定律」?上图则很好的解释了这一问题。从损失曲线来看,训练初期的两条曲线都经历了快速下降,说明两者都在迅速吸收表层特征,而到了 50K 步后 MLP 迅速进入平缓期,而 Transformer 依然在稳步下降,最终稳定在 0.06 左右。
正是因为 Transformer 能够在长达 200K 步的训练中持续保持学习状态,它才有资格和能力去消化那 20 亿帧的海量、长尾、异构的专家数据。即 Transformer 相比于 MLP 在处理高维、连续的机器人运动控制任务时,展现出了更高的理论上限。
- 不同架构、不同数据量间的横向对比
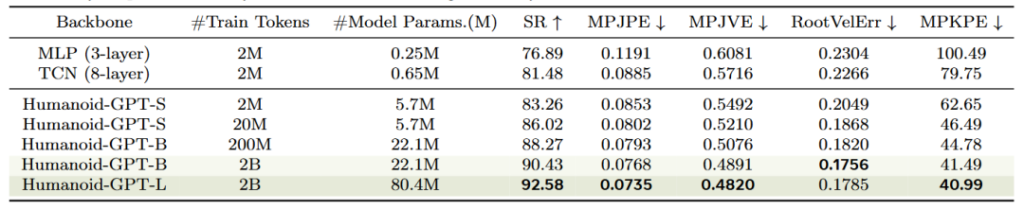
如表(SR 为机器人跟踪成功率;其余都是误差,越小越好),横向对比看,同样是 2M token 的训练数据,MLP 的过拟合问题已经显现(MLP-L 75.25% SR < MLP-S 76.89% SR),TCN 同理,而 Transformer 没有这个问题,小数据的性能也能平稳提升。纵向对比,当参数量为 2B 的 Humanoid-GPT-L 时,所有性能都几乎做到了最好。
由此得出的核心结论是:「扩展定律」 在机器人运动控制中是成立的,但它的成立是有条件的——必须是「Transformer 架构 + 足够的数据规模」。二者缺一个,规律就不一定能体现。

有了「小脑」的机器人更懂控制身体
AstraBrain-WBC 0.5 已在大规模数据处理与「扩展定律」上得到验证,而更关键的看点,是其在真实机器人上的运动表现与泛化能力。

如上表,Humanoid-GPT 对于 4 种完全未见的舞蹈序列,可以做到无微调直接复现(MPJPE、MPJVE代表误差,越小越好),对比其他模型突出了优秀的泛化能力。
此外,银河通用还将英伟达的通用型追踪器 SONIC 和 Humanoid-GPT 分别部署在机器人平台——宇树的 Unitree G1(左边为 SONIC,右边为Humanoid-GPT),直观感受其实机表现。

高动态任务中的二者表现

平衡感任务中的二者表现
以上两图直观看出了二者运动控制模型在能力上的差距,银河通用研究者优化了部署流水线,确保模型规模扩大不会牺牲推理延迟和通信延迟。因此,从银河通用官方演示中看,无论是「遥操作跟随」还是「运动姿态调整」,搭载 Humanoid-GPT 模型的机器人表现都明显强于 SONIC 。
更值得关注的是,AstraBrain-WBC 0.5已能稳定在复杂场景中执行训练数据集中完全未见的高动态动作,如建筑、足球运控射门等双手全身协调任务。


此外,通过轻量微调,还能实现一些极端高动态任务。

最后,作为一款开源模型,银河通用研究者为学术界和工程界感兴趣的工程师贴出了实际算力成本。整个训练过程耗费约 15,000 GPU 小时,其中 75% 用于专家训练(RTX 4090),25% 用于 Transformer 蒸馏(H100)。


小结
对于 AstraBrain-WBC 0.5 发布,相信你无论是关注其作为行业首个达到 GPT-1 量级的人形全身运控大模型,还是震惊于部署了 AstraBrain-WBC「小脑」的机器人所做出的酷炫动作,都会跟我有同样的疑问:银河通用作为只走「轮式底盘+双臂操作」的「务实」机器人公司为什么要和英伟达的 sonic 比翻跟斗?
答案或许恰恰在于此。「翻跟斗」从来不是银河通用的商业目标,而是其验证通用运控能力的试金石。当机器人能够在极端动态场景下稳定控制全身自由度时,意味着同一套能力也有机会迁移到仓储搬运、工业操作、零售服务等更具商业价值的任务中。银河通用想证明的不是机器人会不会翻跟斗,而是自己正在构建一个能够适配未来各种机器人形态的「通用小脑」。