
4 月 7 日,具身智能企业千寻智能宣布完成新一轮 10 亿元融资。
本轮融资由顺为资本、云锋基金联合领投,达晨财智、某头部人民币基金、银河源汇、图灵基金、新鼎资本、庚辛资本等加持。
据悉,这也是千寻智能在 2 月完成近 20 亿元融资后,在 30 天内完成的新一轮融资,累计融资额达到 30 亿元。
值得注意的是,千寻智能成立于 2024 年 1 月,在不到两年半时间内估值突破 100 亿元。进入 2026 年后,其融资节奏也明显提速,短期内连续完成大额融资。
在技术路径尚未完全收敛的背景下,这样的融资密度并不多见。所以一个更值得讨论的问题是,千寻智能的技术路线,与当下主流有何不同?

不靠「干净数据」的模型
对于目前的具身行业来说,单纯做本体和运动端的表现,已经不容易拿到特别大金额的融资了,并且估值也很难快速拔高。
近半年来,这个趋势也变得更加明显,毕竟机器人要想真正进厂、进家大规模落地应用,解决具身模型(大脑)是更重要的事情,小脑方面的运控表现给大家带来的刺激已经开始边际效应递减。
而在具身模型方面,行业内的主流大致是 VLA 和世界模型两种路线,大家各有侧重。
从对外信息看,千寻智能的重点是一套端到端的 VLA 模型体系。不过他们并没有过度强调「干净数据」,其年初开源的 Spirit-v1.5 模型反而认为「干净的数据是优秀机器人基础模型的敌人」。
- 精心设计的任务:编写脚本化的操作,以确保采集过程中的一致性和高成功率。
- 可控物体放置:物体放置在可预测、易于到达的位置。
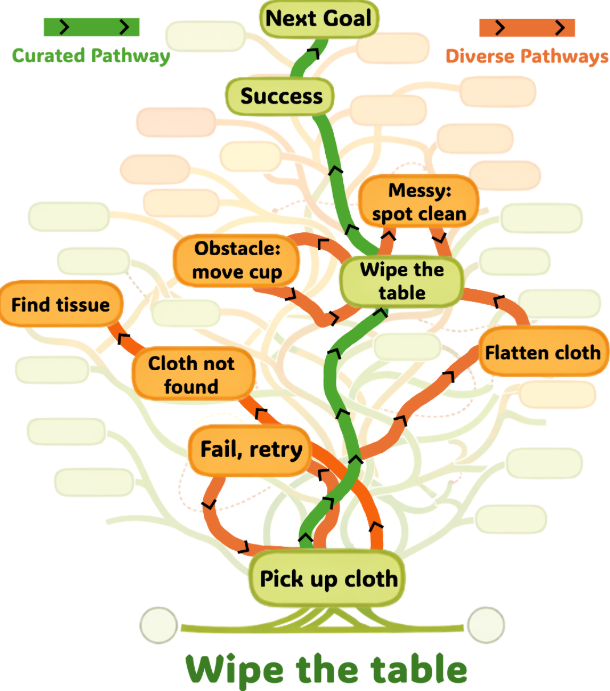
对于机器人来说,这类「干净数据」看起来价值很高,噪声低、任务逻辑也相对清晰,在实验室场景有较高的任务成功率。
在千寻智能看来,实际落地应用时,这种「完美」的数据往往会限制模型的泛化能力,如果机器人只在一切都完全可见且可到达的环境中学习,那在多变的现实环境中,很可能就会失败。
对此,千寻智能团队在数据方面,更看重数采员「即兴发挥」采来的数据,即在任务大目标确定的前提下,怎么去完成任务由数采员自行决策。
在团队的相关实验中,在微调阶段,使用多样化数据集训练的模型在收敛速度和最终性能方面优于基于演示数据集的模型。具体来看,多样化数据集模型达到相同性能所需的迭代次数比基线模型减少了 40%。
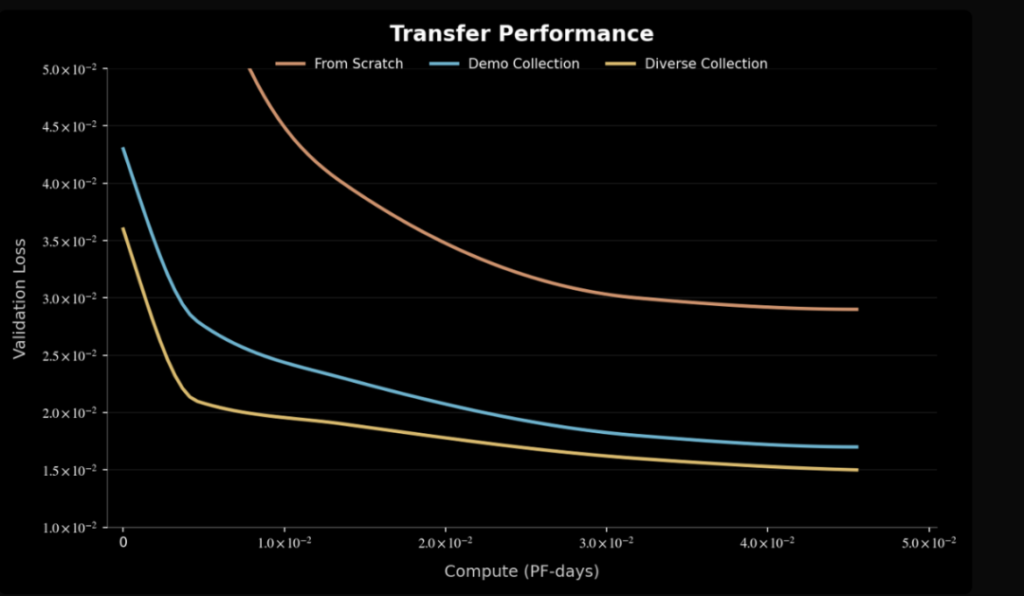
在训练方式上,该团队采用的方式也很像大语言模型,先用互联网视频数据预训练,大语言模型中这里通常是文本数据,而后团队会用真实交互数据对齐。这样的路线相当于先培养模型的世界理解能力,而后再发力具体任务。
值得一提的是,在规模化有效性的研究上,千寻智能也发现随着数据集的增长,新任务的验证误差会持续下降。
这点倒是和美国具身企业 Generallist 对 Scaling Laws 的追求不谋而合,千寻智能联创高阳曾在去年中国人形机器人与具身智能产业大会上,强调数据规模对模型性能的重要性,并指出数据量与模型的泛化能力呈幂律关系。
从这个角度,也可以看出千寻智能的模型路线走向,即不通过清洗数据来提升成功率,主要通过扩大分布来获得泛化能力。
这实际上就是在把具身智能的问题,从任务建模转成更典型的,数据规模加数据分布驱动的问题。
这也是为什么,千寻智能此后的动作,多数都在围绕「数据」展开。

「多样性数据」路线驱动
对于机器人来说,如果说模型决定方向,那数据体系决定的就是这条路线能不能跑通。
从目前披露的信息来看,千寻智能在数据上的核心思路非常明确,即优先放大数据分布,走「多样性数据」路线。据了解,目前已累计获取超 20 万小时的多类型真实交互数据,主要包括:
- 互联网视频数据:用于预训练阶段,提供大规模的视觉与物理世界先验。
- 遥操作数据:学习具体任务执行过程。
- 可穿戴设备采集数据:记录更自然的人类操作方式,提供非标准操作路径。
在这些数据来源中,千寻智能核心投入之一,其实是在可穿戴采集体系上。据悉,其自研的可穿戴设备已经迭代到第 5 代,并且把数据采集成本压缩到了传统方式的约 1/10。
这也让数据采集可以从实验室行为,变成可扩张的生产行为。在这种基础上,千寻智能也选择了将数据团队扩展至千人规模。公司也预计,2026 年其数据总量将会突破 100 万小时。
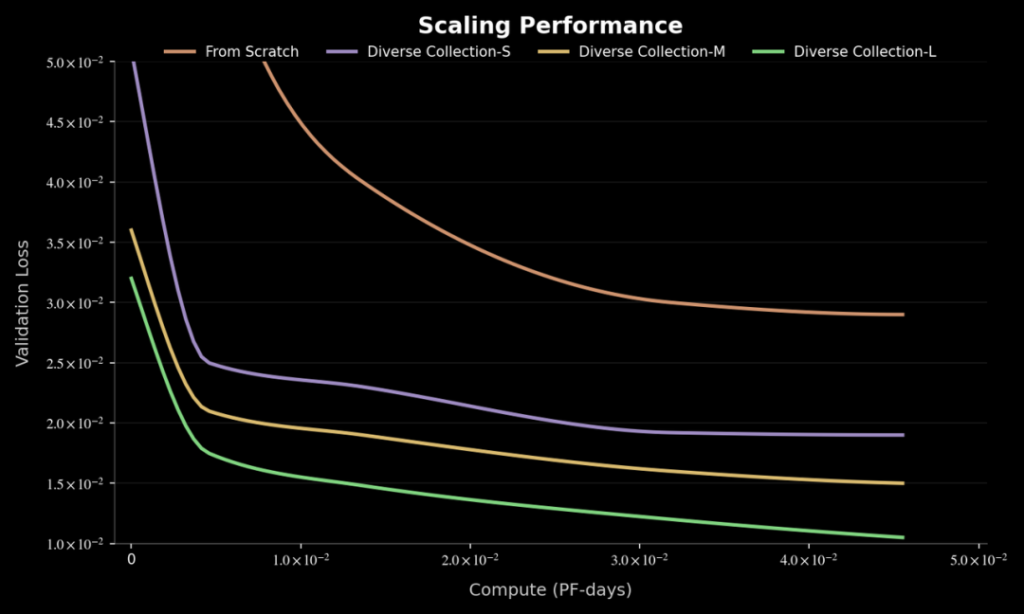
结合前面提到的机器人领域的 Scaling Laws 来看,当采集成本足够低时,扩大规模本身就是提升能力的一种手段。
值得一提的是,在预训练阶段,千寻智能也选择用互联网视频数据融合可穿戴数据,来帮助模型学习现实世界的基础常识。在具体的任务上,团队采用遥操作数据来监督微调,而后会通过强化学习,使得模型可以在真实环境里持续推演、产出新数据,再用这些数据反向训练、完善模型。
不过需要注意的是,这套数据体系也有一个非常明确的前提:
- 多样性数据本身会带来更高噪声。
- 模型训练初期相对难以收敛。
- 对数据规模的依赖性强。
这更像是一条典型的规模驱动路径,在数据持续增长的情况下,长尾问题会被覆盖,模型的稳定性和泛化能力才会真正体现出来。
所以,千寻在模型之外,把大量资源都投入在了数据体系的建设上。

现阶段商业化重点不在利润
从目前的落地动作来看,千寻智能的重点并不在短期变现,服务于技术还是最重要的目的。
这也是目前整个行业都在追求的事情,即机器人落地部署、回流数据、反哺模型、提升能力、增加部署规模的闭环。
这套闭环本身并不复杂,但执行起来门槛很高。几乎所有团队都在讲这件事,关键就是有没有稳定的真实场景去不断触发这个循环。

从这个角度看,千寻和京东的合作,更像是一个数据节点。Moz 机器人在京东 MALL 制作咖啡,咖啡制作本身不是关键,重要的是场景特征:
- 有明确任务边界,便于评估。
- 有足够重复频次,容易积累数据。
- 不是完全标准化,能够产生变化。
这类场景,不像实验室一样干净,也不像完全开放环境那样失控,更接近一个中间状态。对千寻来说,这样的部署点的价值在于,它可以持续产生带有扰动的真实交互数据,而不是一次性的演示数据。
这些数据再进入训练和微调流程之后,模型的变化就不再只是离线优化,而是直接对应真实运行中的问题。
如果这样的节点数量增加,那么模型迭代的节奏,也会逐渐从阶段式更新,变成更连续的过程。
把模型、数据和落地放在一起看,千寻智能走的也是一条 Scaling 的技术方案。
从京东 MALL 的场景落地,到预计 100 万小时的数据积累,千寻智能也在等待具身模型的能力会在某个临界点迎来质变。
因此,在这条路上,数据也成为了 2026 年整个具身行业最关注的问题。