
最近,美国具身智能公司 Physical Intelligence 的联合创始人 Sergey Levine 参加了播客节目《Invest Like The Best》,在 1 个多小时的访谈中,Sergey Levine 就机器人模型路线、数据飞轮、本体硬件等问题进行了详细探讨。
作为一家主做软件的具身公司,PI 的商业模式是给其他机器人团队提供模型,这点也类似于给汽车提供智驾系统的软件公司。并且在去年底完成 6 亿美元融资后,PI 的估值达到 56 亿美元(约合人民币 385 亿元),比不少全栈自研的具身公司估值都要高。
另外,身为 PI 的联创,Sergey Levine 同时也是 UC 伯克利大学计算机副教授,其谷歌学术引用量达 18 万次,在机器人等领域具有一定的影响力。

在行业共同关注的数据领域,Sergey Levine 认为,现阶段量化终极数据集的规模不是首要问题,打造能落地执行多样化任务、持续采集数据的实用系统是更关键的事情。
而对于机器人大规模进入家庭这件事,Sergey Levine 表示,如果在 2050 年机器人还没进入家庭干活,那很可能就是因为应对场景的多样性,和技术与人类社会交互的长尾挑战还没有很好地解决。
所以在这个过程中,PI 一直就想打造一套像操作系统一样的底座,从而适配各种类型的本体硬件。

数据先跑起来最关键
相比较大语言模型,机器人行业的数据问题,更加复杂。Levine 也提到一个关键差异,就是机器人没有「互联网级数据」。基本没什么统一格式的情况下,还没有低成本的标注。
所以目前行业在数据方面的路径大致分为两种:
- 真实世界 + 数据驱动,采用大量真实数据,多任务学习,打造通用模型。特点是泛化强,贴近真实场景,但规模化的数据采集成本很高。
- 仿真驱动,模型主要在仿真环境中学习,成本低,也可以模拟一些极端危险场景。但仿真与真实物理世界之间通常存在一些微观误差。
PI 走的路线是前者,比较重视真实数据,但 Levine 也没有盲目自信,他提到这两条路线未来要么融合,要么其中一条胜出,并不一定真实数据的路线就一定能走到最后。

目前而言,PI 的策略,还是非常接近特斯拉的自动驾驶逻辑,Levine 表示,核心是让系统先具备实用价值,能走入现实世界自主采集更多数据,就像特斯拉从不担心车辆数据量,甚至数据多到处理不完。关键不在于量化终极数据集的规模,而在于打造能落地、能执行多样化任务、持续采集数据的实用系统。
这就是机器人版的数据飞轮,也是现在很多机器人公司都在提、也最想去落地推动的事情:
- 让系统先能用起来,尽管不完美,能在真实环境中持续执行任务是核心。
- 在使用中采集数据,这个过程中用户得到了使用价值,整个系统也有了持续学习,产出数据的载体。
- 反哺模型,实际落地中产生的数据可以让模型不断优化策略,从而提升能力。
但这里有一个更深的变化,就是数据的重心正在迁移,过去机器人依赖精确控制数据、人工标注轨迹和动作级监督。
而现在,Levine 提到一个非常关键的技术点:只用「语言标注」,也能优化机器人。也就是说,机器人犯错时,不需要再教机器人怎么动,用语言标注哪里做错了,模型就可以得到改进。
这也就意味着机器人正在逐渐进入一个弱监督时代,类似大模型从精确标注走到大规模弱监督,从动作学习走到语义学习,这一步也是机器人走向规模化的关键。

操作系统一样的底座更加重要
在机器人本体硬件领域,通常也有两种设计方案,一种是专用机器人,像物流、洗碗机器人,它们能在细分场景中执行专业任务,一旦换个场景,就会没有用武之地。
另一种则是通用人形机器人,目标是执行人类可以做到的一切任务,通用性很强,但研发难度非常高。
在 Levine 看来,这些都不是主要问题,所有机器人面临的智能核心挑战是一致的。造出一个像操作系统一样的底座是更重要的问题,而后大量本体硬件形态在这上面爆发,才是更合理的路径。并且优秀的基础模型应与机器人形态解耦,能自主适配操控的躯体与工具。

这也是他对 physical intelligence 的定义,目标是开发能控制任何具身系统去执行「任何任务」的机器人基础模型。
在这里 Levine 也用大语言模型和机器人模型进行了比较:
- 语言模型能一统各类应用场景,核心是它能利用更广泛的数据来源。这并非简单整合各场景数据,而是通过弱监督数据习得更全面的世界认知,建立底层认知基础,在此之上搭建各类应用,效率会大幅提升。
- 在机器人领域,世界认知能力更关键。人类能快速掌握新技能,是因为我们理解物理规则,能凭直觉预判陌生场景的结果,快速举一反三。如果能整合多来源、多场景、多机器人的数据,就能让模型具备物理认知能力,后续在该平台上拓展新应用会更加轻松。

在这个基础上,PI 一直以来的路径都是优先模型算法层面的研发,尽管机器人行业有这么一句话流传:「如果你从事机器人领域,却不全力以赴解决硬件问题,无论成本如何,你都不会成功。」
这句话正是出自 Figure 创始人,这家公司有着机器人行业全球最高的 390 亿美元估值。

如果 25 年后机器人还不能走进家庭
自从这两年机器人开始大规模走进大众视野后,人们就一直在期待着机器人能真的走进家里,帮助自己处理一些家务。
但因为技术成熟度的限制,尤其是模型,很多机器人干活的样子大家也只能通过短视频 Demo 来了解,不过近一年随着模型、数据、硬件等领域的发展。
不少机器人从业人士对机器人进家这件事开始更加积极,5 到 10 年左右也是一些 CEO 经常提到的数字,对应的时间节点大概在 2030 到 2035 年。
「如果到 2050 年,厨房仍没有机器人帮忙洗碗,最可能的原因是什么?」

Levine 对此表示,如果是这样,那核心阻碍可能就是技术与人类社会交互的长尾挑战,在技术层面,最大的风险就是应对场景的多样性。
- 技术与人类社会交互的长尾挑战:和自动驾驶类似,技术达标只是一方面,公众对技术的接受度、对不完美表现的容忍度,也是很大的问题。
- 应对场景的多样性:清洁酒店客房、餐厅辅助厨师等相对可控的复杂场景,我们有把握攻克。但家庭环境充满不可预知的突发状况,需要模型精准预判、智能适配。当任何情况都可能发生,且机器人会真实影响物理世界,就必须保证每一次决策都合理可控,行为必须符合人类预期。
而且对于机器人进入家庭来说,最难的任务就是扶老人起床、给婴儿换尿布这类照护型的任务,有非常高的风险,互动时容易伤到人类。
这些对于机器人来说是终极挑战,也是最容易让低估难度的领域。

中层推理环节是当下核心
在目前机器人行业技术路径尚未完全收敛的情况下,Levine 也简单透露了当下 PI 的研发核心是中层推理环节。
他提到,要想实现泛化,必须依托常识知识,而知识的表征形式至关重要。大语言模型擅长文本转换,但机器人需要空间、语义等多维度认知。
这背后其实意味着一个行业共识正在逐渐形成,机器人最大的瓶颈,已经从动作执行,转向决策与理解。
更重要的变化是,推理的表征形式,也在慢慢发生转变。
过去一年,很多机器人系统开始引入类似大模型的思维链,先用语言拆解任务,再逐步执行动作。这在早期非常有效,相当于把大模型的能力外挂到机器人上。
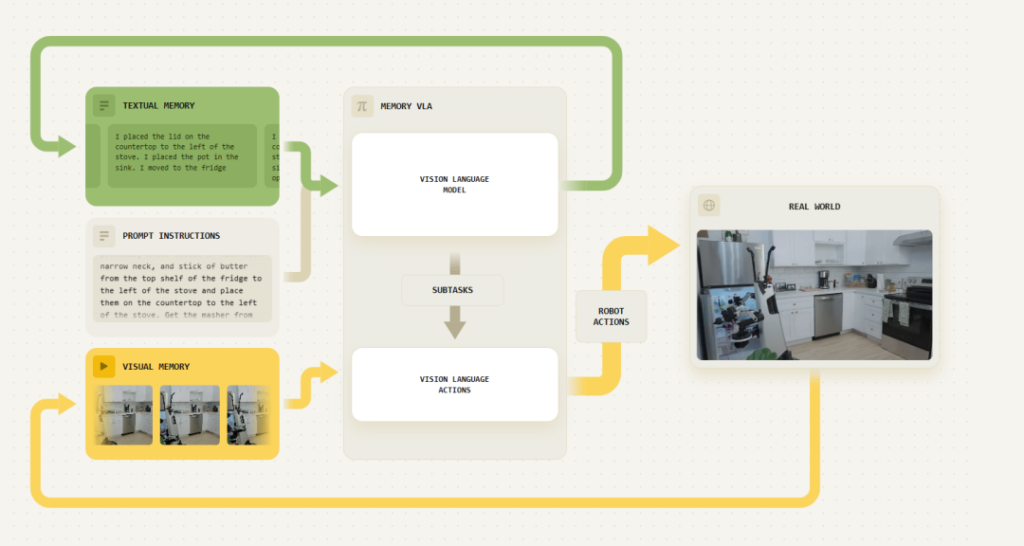
但在落地过程中,大家也慢慢发现,语言并不是物理世界的高效表示。如果把机器人面对的空间关系、物体状态和连续变化 这些信息如果全部转成文本再推理,不仅低效,而且容易出错。
这也是 Levine 提到的关键点,需要新的「知识表征方式」,而不是单纯依赖文本。当前行业正在探索的方向,是把推理从「显式语言」,逐渐转向「隐式结构」。
简单理解就是,不再用碎碎念式思考,重点是在模型内部,直接形成空间+语义+动作的联合表示。类似于人在做事时,并不会在脑中逐句说话,而是直接形成直觉判断。

写在最后
把这场对话放回到整个机器人行业来看,会发现 PI 的选择,其实非常明确:
- 在数据上押注真实世界和数据飞轮。
- 在系统上强调类似操作系统的通用底座。
- 在模型上,下一步重点放在中层推理与表征方式。
在机器人领域,这是一条更慢、更长,但也更深的技术曲线,而且还要接受短期内难以看到明显经济效益的现实。
所以,对于业务重心都在软件上的 PI,数据飞轮并不容易推动,他们更需要将模型算法做到极致,才会有大规模硬件对此买单。