
4 月 9 日,智元发布了新一代 VLA 基座模型 Genie Operator-2(GO-2),引入「动作思维链」和「异步双系统」架构的同时,试图为机器人领域长期存在的知行不一问题,给出一套新的解法。
近一年来,围绕机器人落地干活的讨论越来越多,其中,VLA 模型被很多人认为是相对直接的技术路径,它通过统一建模,把感知、理解和执行压缩进一个模型中,具备一定的泛化能力。
不过在行业逐渐将其推向实际部署的过程中,一些问题也开始变得具体:如果单把语义理解与推理、运动表现拿出来,能力看起来都没什么问题,可只要走进具体任务,理解意图和稳定完成之间,往往就存在着巨大落差。
就好比机器人在收到拿水杯的任务指令后,能在脑海中推出一条完美路径,但只要一上手,动作就容易偏离规划,导致任务失败,这就是机器人领域非常典型的语义 ‑ 运动鸿沟。
在这样的落差下,行业开始重新思考,机器人到底该边想边做,还是应该先想清楚再动手。

围绕这些问题,GO-2 更强调机器人要想清楚再做,并提升执行任务时的稳定性。
而这其中的关键,就在于其新引入的动作思维链和异步双系统架构。

从链路割裂到动作思维链
在传统范式下,机器人通常遵循一条相对割裂的路径,高层模型完成语义理解与推理,输出抽象指令;再由中间模块进行任务拆解;最后交给控制系统生成具体动作。
这条链路看起来比较流畅,但问题也出在这里,每一层之间都存在明显的信息压缩和表达变化,从语言到符号,再到控制信号,语义逐渐被「离散化」,而动作需求却是连续高精度的。
尤其是在实际部署中,为了提升响应速度,很多系统会在执行阶段弱化甚至绕过规划过程,转而依赖感知到动作的即时映射。这种方式在短链路任务中表现尚可,但一旦进入多步骤、长时序任务,就容易暴露出明显问题:
- 每一步都在做局部最优决策,缺乏全局一致性。
- 小误差无法被及时纠正,从而不断累积。
- 动作逐渐偏离初始目标,最终导致任务失败。
在这些问题上,如何生成「可执行」的动作规划,并在真实环境中「稳定执行」该规划,就成了技术关键。
所以,智元 GO-2 其中一个关键设计就是引入了「动作思维链」,不在语言或视觉空间中进行推理,而后将结果转换为动作,反而是直接在动作空间中完成这一过程。实际上就是把「中间决策过程」给显式化。
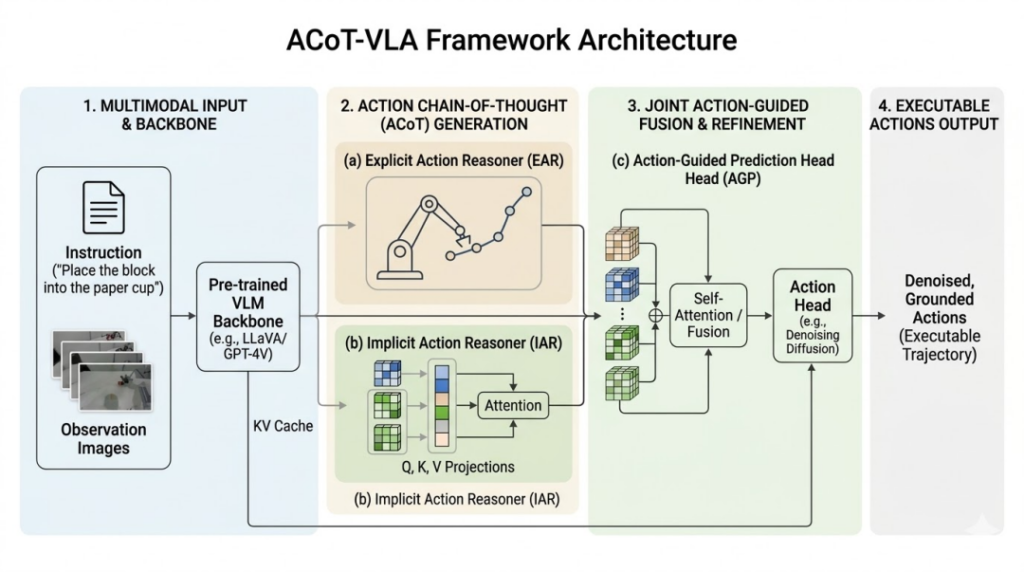
具体来看,模型在接收到任务后,并不会立即输出底层控制信号,会先生成一段高层动作序列。这段序列不是简单的指令集合,是对整个任务执行路径的结构化表达,包含了行为的顺序、阶段划分以及整体方向。
这意味着,模型的思考过程本身就是一条尚未执行的动作路径。
在这种设计下,复杂任务不需要通过额外模块进行拆解,会被自然展开为一系列有序的动作步骤。执行系统所接收到的不是临时生成的控制信号,是已经具备结构的行动方案。
由此带来的变化是,机器人从「边看边做」的即时反应模式,转向「先形成路径、再逐步执行」。执行过程始终围绕这条动作序列展开,小范围偏差可以被局部修正,而整体目标不会轻易漂移。
也就是说,规划本身就已经是一种可执行表示,不是需要再次转换的中间结果。

异步双系统把想和做拆开
在 GO-2 的设计中,动作思维链的主要发力点还是推理该如何进行、放在哪里推理的问题。但对于机器人来说,如何把想好的东西,在真实世界中稳定执行出来同样是一个不可忽视的问题。
在很多机器人系统中,规划往往是一次性的,模型先给出一个完整方案,然后执行模块按步骤展开。但现实环境是持续变化的,这种先想完再执行的方式,很容易在中途失效,只要某一步出现偏差,后续动作就会逐渐脱离原本路径。
在这个问题上,GO-2 的做法是在系统层面引入一种「异步双系统」架构,将「规划」和「执行」拆分为两个不同节奏的模块:
- 慢系统:包含动作思维链,这一部分不会频繁更新,会持续给出一个相对稳定的动作方向。它不是一次性生成完整计划,会不断向前推进,逐步展开动作路径,让整体行为始终围绕一个清晰的结构运行。
- 快系统:这一部分直接面对真实环境,以更高频率生成控制信号,对每一个细节进行调整,比如位置误差、接触变化或者外部扰动。
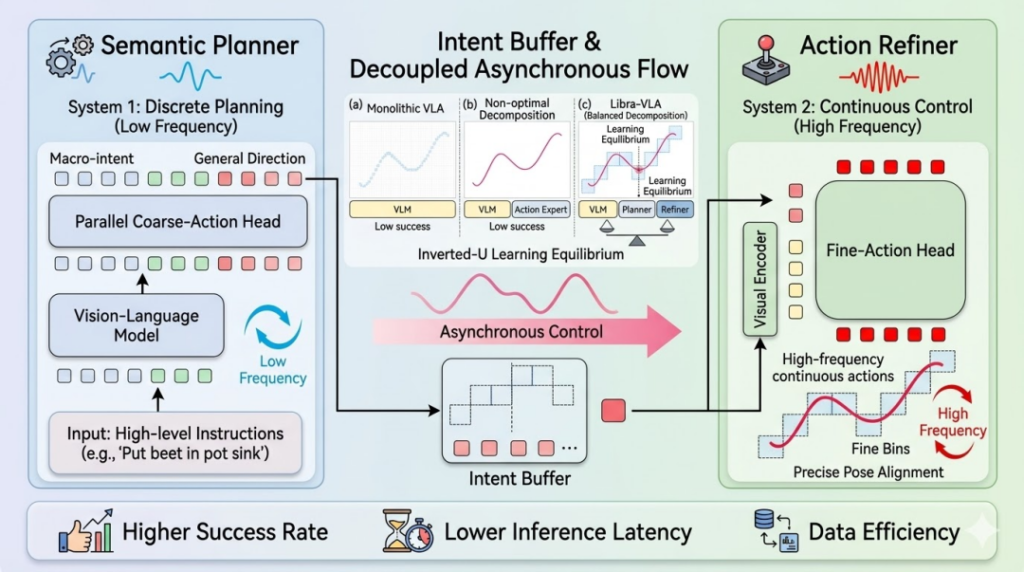
关键在于,这两部分的关系并不是规划到执行的一次性传递,更像是一种持续约束,执行并不是在复现规划,关键在于不断对齐它。
也就是说,每一个具体动作,既要响应当前环境,又不能偏离整体路径。局部可以调整,但方向不能丢。
为了让这种对齐在现实中成立,GO-2 在训练阶段引入了带噪声的强制教学机制,在训练执行模块时,使用真实的高层动作序列作为条件输入,同时人为加入扰动,模拟规划本身的不完美。
这一步的作用在于,让系统习惯于现实世界的状态。规划不完美、环境在变化,但执行依然可以稳定进行,而不是一旦出现偏差就迅速失控。

落地深度也是模型系统的一环
如果把前面的变化理解为系统内部被重新组织,那么在结果层面,GO-2 至少给出了一个相对明确的反馈,这套结构正在发挥作用。
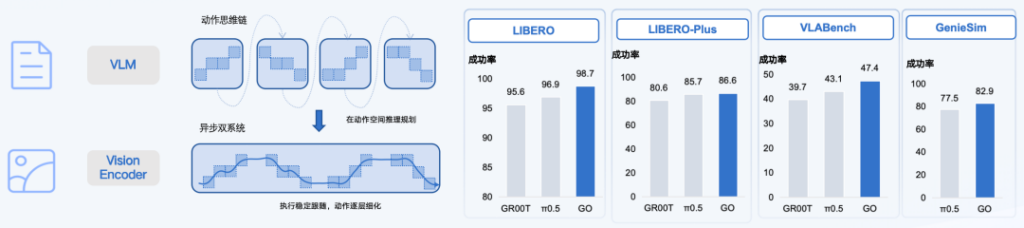
在多个主流具身智能基准测试中,GO-2 也取得了一定的成绩,比如在 LIBERO Benchmark 中:GO-2 模型在 Spatial、Object、Goal 与 Long 四类任务上平均成功率达到了 98.5%。
不过,比这些数字更值得关注的,是它背后所对应的一种能力转变,模型开始具备在真实环境中长期运行的条件。
GO-2 在这一点上的思路,其实很直接,不把模型当成一次性训练完成的产物,而是把它放进一个持续运转的系统里。

一方面通过预训练建立起通用能力,另一方面在真实任务中持续学习。系统用得越多,反馈越多,模型也随之不断提升。
更重要的是,部署过程本身也逐渐成为了能力训练的一部分,从这个角度看,未来衡量模型能力的标准,可能还要加上关键的实际落地深度。